

Open-Sora: Colossal-AI开源的类Sora架构视频生成模型
Open-Sora是一个开源Sora复现方案,旨在帮助用户构建类似于OpenAI Sora的视频生成模型。它提供了一个完整的开发流程,包括数据处理、模型训练和部署,支持动态分辨率和多种模型结构。,Open-Sora是一个开源Sora复现方案,旨在帮助用户构建类似于OpenAI Sora的视频生成模型。它提供了一个完整的开发流程,包括数据处理、模型训练和部署,支持动态分辨率和多种模型结构。
OpenELM是Apple苹果公司发布的一系列开源语言模型,包含OpenELM-270M、OpenELM-450M、OpenELM-1_1B和OpenELM-3B不同参数规模版本(包含预训练和指令微调)。
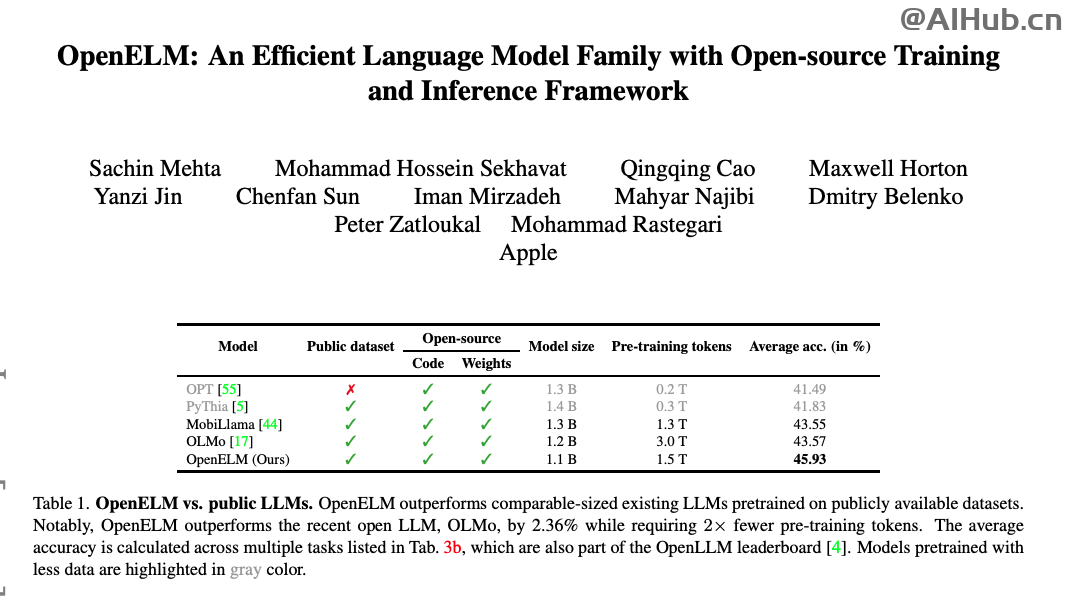
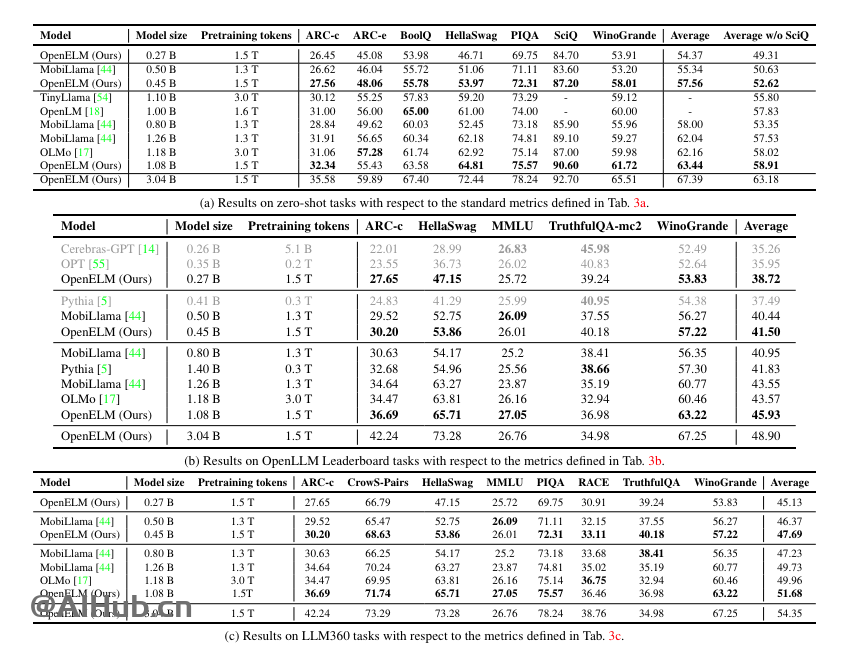
OpenELM通过高效的层级缩放策略实现了优异的性能,来有效分配Transformer模型每一层参数,从而提升准确率。在参数预算约为10亿的情况下,OpenELM 的准确率比OLMo提高了2.36%,预训练token需求减少了2倍。
OpenELM不仅开源了模型权重,还包括了训练和评估的完整框架,如训练日志、checkpoints和预训练配置。他们还发布了将模型转换为 MLX 库的代码,以便在 Apple 设备上进行高效推理和微调。而且,苹果还开源了神经网络库CoreNet。
OpenELM 的这些技术架构设计使其在保持较小模型尺寸的同时,能够实现与大型模型相媲美的性能,这对于希望在资源受限的环境中部署高效语言模型的研究者和开发者来说是非常有价值的。
在与现有公开可用的大型语言模型(LLMs)的比较中,OpenELM在预训练令牌数量较少的情况下,表现出了更高的准确率。例如,OpenELM在参数数量约为11亿(1.1 B)时,比参数数量为12亿(1.2 B)的OLMo模型高出2.36%的准确率,同时预训练所需的令牌数量减少了2倍。
苹果开放了OpenELM的论文、代码和模型,相关资源链接如下:
OpenELM其开源性质和跨平台支持为自然语言处理领域的研究者和开发者提供了宝贵的资源,推动了开放AI研究的进展。
