

Gen-2
Runway最新推出的AI视频生成模型
DeepSeek-V2 基于 2 千亿 MoE 模型底座,领先性能,超低价格,越级场景体验,已在对话官网和API全面上线。,DeepSeek-V2 基于 2 千亿 MoE 模型底座,领先性能,超低价格,越级场景体验,已在对话官网和API全面上线。
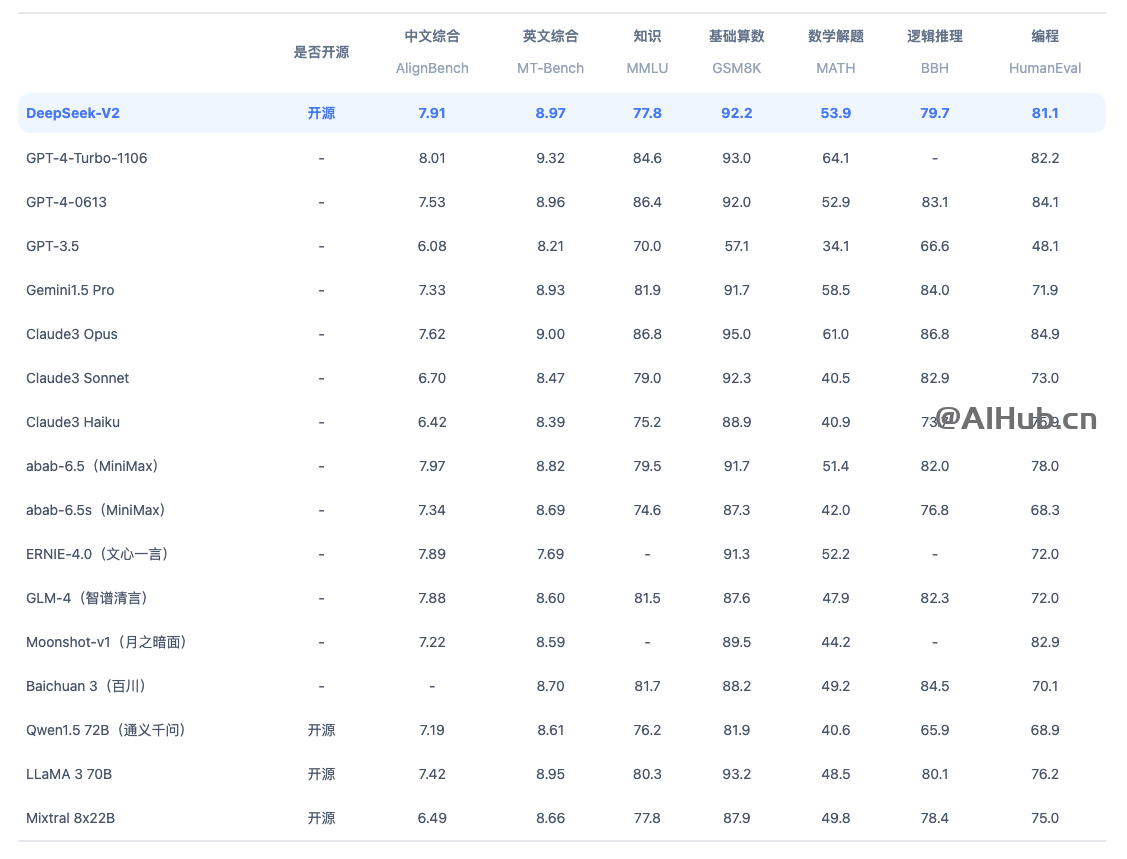
DeepSeek-V2是由杭州深度求索公司发布的第二代开源MoE模型,DeepSeek-V2 在中文综合能力与 GPT-4-Turbo,文心 4.0 等闭源模型在评测中处于同一梯队,英文综合能力英文综合能力(MT-Bench)与最强的开源模型 LLaMA3-70B 处于同一梯队,超过最强 MoE 开源模型 Mixtral8x22B,特别擅长数学、编程和逻辑推理任务。它在多个大型模型排行榜上名列前茅,支持长达128K的上下文长度,并提供开放源代码。

DeepSeek-V2 是一个在多个领域表现出色的人工智能模型,其综合能力如下:
DeepSeek-V2 的API定价如下:
DeepSeek-V2 的对话官网和API服务都已上线。不懂技术的用户可以在线体验,开发者可以接入API服务,开发自己的AI应用。
综合来看,DeepSeek-V2 是一个多功能、高性能的AI模型,适用于需要处理复杂数学问题、编程任务和逻辑推理的应用场景,同时它的定价和兼容性也使其成为企业和技术开发者的一个经济实惠且实用的选择。
