

MyBot.Chat
用于客户支持和潜在客户生成的AI聊天机器人构建工具。
随着科技的飞速发展,人工智能已深入到各个领域。为响应古籍活化利用号召,推动大语言模型与古籍处理深度融合,以古籍智能化的研究为目的,南京农业大学国家社科基金重大项目“中国古代典籍跨语言知识库构建及应用研究”课题组与中华书局古联公司推出了一系列古籍处理领域大语言模型:荀子古籍大语言模型。
荀子不仅是我国先秦时期伟大的朴素唯物主义的思想家,也是一位散文大家。他在语言学理论的阐述上又是一位开拓者、奠基人。荀子系列专为古籍智能处理而设计,这一系列模型的推出将推动古籍研究与保护工作的新发展,提高中华传统文化传承的效率与质量。
“荀子”古籍大语言模型整合了包含《四库全书》在内绝大多数传世古籍文献在内的超过20亿字的语料库。它以推动古籍研究和保护创新发展、提高中华传统文化传承效率和质量、实现大语言模型与古籍处理深度融合为宗旨。
本次荀子系列模型开源包括两个部分:基座模型XunziALLM与对话模型XunziChat,模型的调用方式与阿里云的Qwen系列大模型一致。用户可以在GitHub和ModelScope等网站免费下载使用。
荀子系列模型主要功能包括:智能标引、信息抽取、诗歌生成、高质量翻译、阅读理解、词法分析、自动标点等,可显著提高古籍处理和研究的效率。
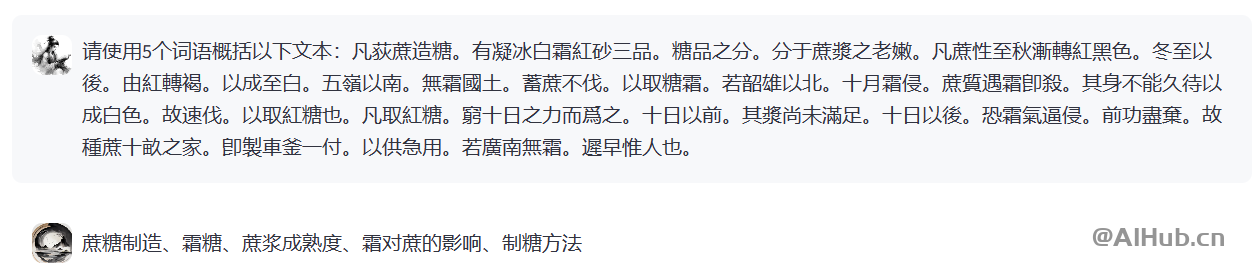


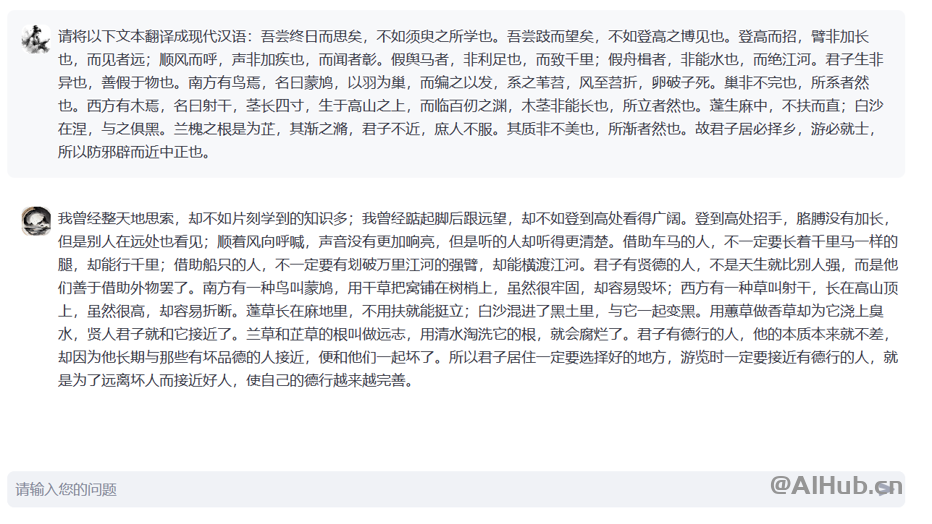
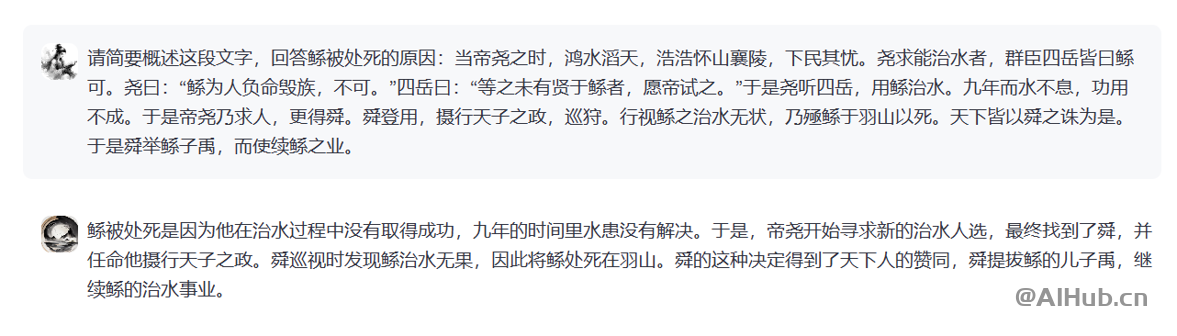

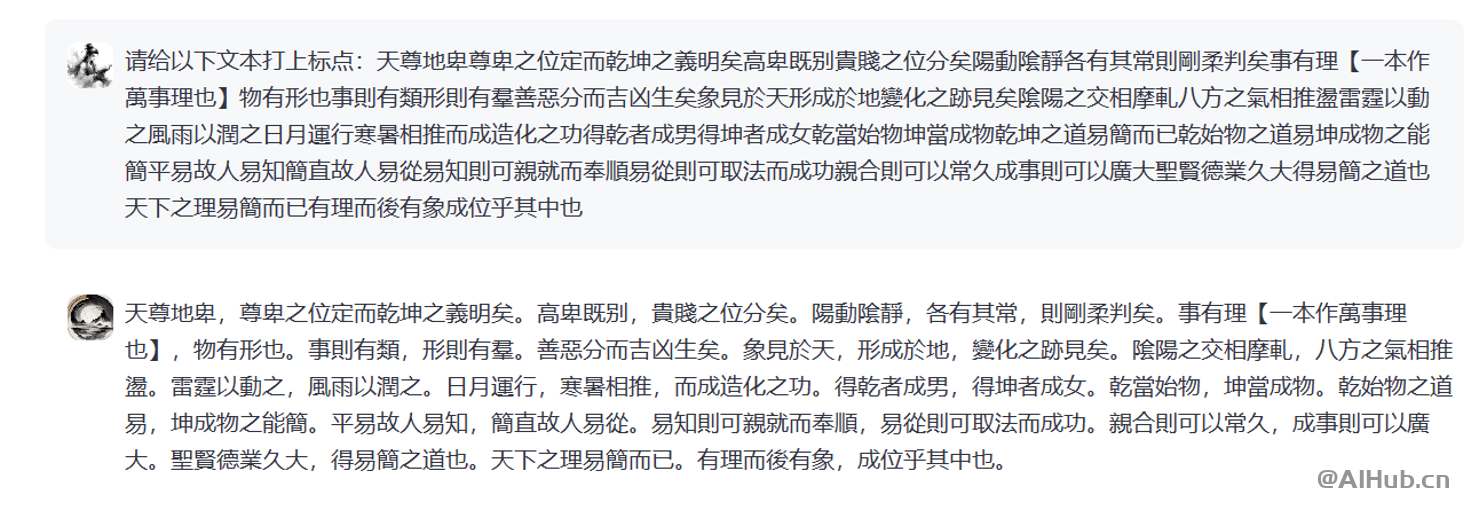
由于我们同时发布了基座模型,用户也可以根据自己的需求,使用本地的训练语料微调荀子基座模型,使得其能够在古籍下游处理任务上取得更佳的处理性能。
你可以在GitHub和ModelScope等网站免费下载使用。
